Yes, this is yet another post about bugs in CFF Explorer. So far I've described:
Today, I'll describe an issue with CFF Explorer's RVA2Offset function and provide a solution to the problem (patched executable).
And no, I really don't hate CFF Explorer. In fact, it's one of my favorite tools and I use it every day - that's why I keep noticing more and more issues with it. 😉
Introduction
Here is an executable that demonstrates the bug: https://www.mediafire.com/?9ju0cfm36b32ys9
If you open it in CFF Explorer and try to check Import Directory. In this case, CFF will show that it's empty.
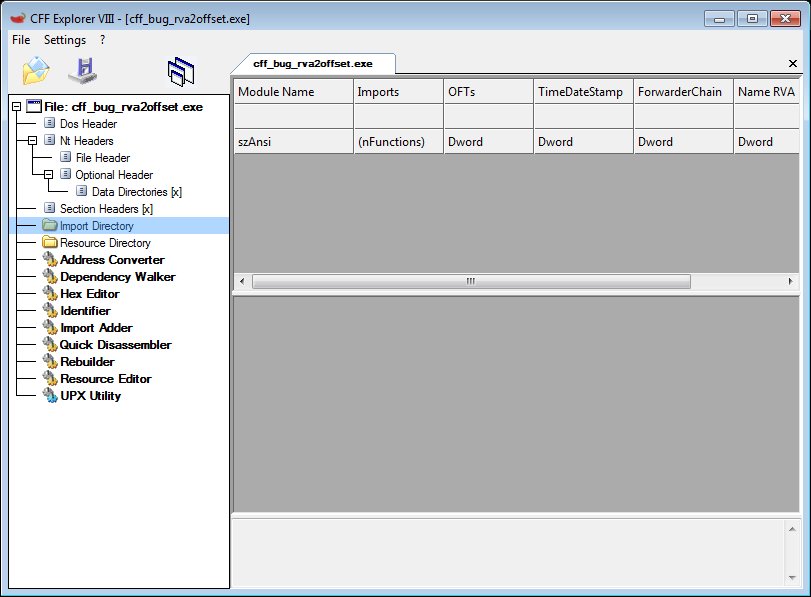
That's incorrect, import directory of this executable is present and valid. It contains 2 DLLs and 3 APIs:
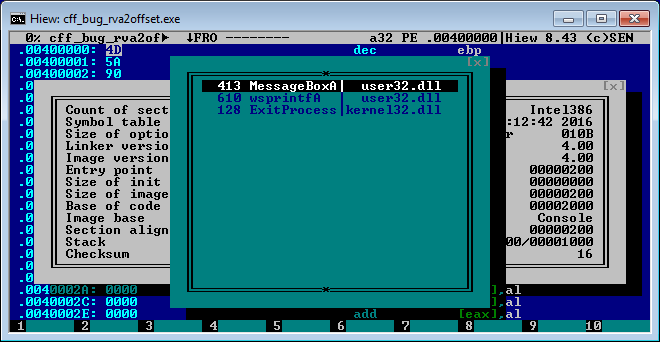
In other executables, it can get stuck into eternal loop or - even worse - show incorrect data.
Also, CFF's Address Converter feature is affected. In my demo executable, try convert RVA 0x2000 to file offset. It will return 0:

So, what's happening here?
Background of the bug
To put it simply, bug is triggered when one section in executable has SizeOfRawData much larger than VirtualSize. In my crafted executable it looks like this:
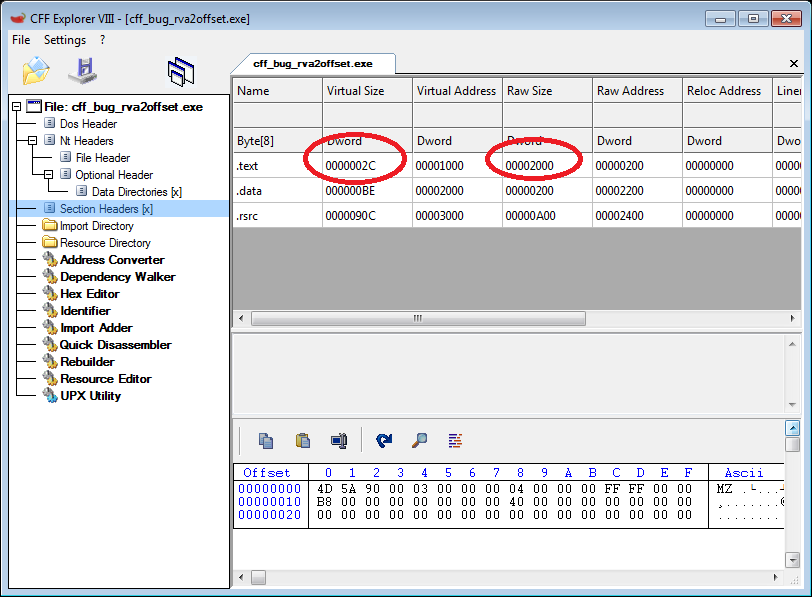
Nitpickers corner: it's actually more complicated. The exact condition is ALIGN_UP(sec.SizeOfRawData, pe.FileAlignment) > ALIGN_UP(sec.VirtualSize, pe.SectionAlignment). But who cares about those small details, anyway?
And the offending pseudo-code in CFF Explorer looks something like this:
foreach (SectionHeader sec in SectionHeaders)
{
// try to calculate how much data this section actually contains. This goes wrong, if physical size > virtual size.
dataSize = sec.sizeOfRawData ? align_up(sec.sizeOfRawData, pe.fileAlignment) : sec.virtualSize;
// check if our RVA falls into this range
if ( RVA >= sec.virtualAddress && RVA < dataSize + sec.virtualAddress )
{
// if so, convert RVA to offset
return (RVA - sec.virtualAddress + sec.ptrRawData);
}
}
Fixing the bug
Since I'm doing binary patches to CFF Explorer, I'm quite limited to what I can do and how. In the end, I chose the following pseudocode:
// calculate how much data this section actually contains.
dataSize = align_up(sec.sizeOfRawData, pe.fileAlignment);
if (dataSize > align_up(sec.virtualSize, pe.sectionAlignment))
{
dataSize = align_up(sec.virtualSize, pe.sectionAlignment);
}
While it doesn't look like much (and it doesn't cover edge cases, for example, when PE file is truncated), in general it should work just fine.
Download link for fixed CFF Explorer: https://www.mediafire.com/?5eg1bs9a9bv39ge
It also includes all my previous fixes.
Conclusion
While writing this post, I noticed that PE viewer in ExeinfoPE v0.0.4.1 has very similar bug. And ProtectionID v6.6.6. And PETools 1.5 Xmas edition. And Stud_PE 2.1. And LordPE. And then I ran out of tools to test. 😀
Obviously, I can't fix them all. All I can say - use PE editing/viewing tools that actually work, for example, HIEW or IDA. And when you're writing your own PE parser library, make sure you test it on weird executables.
Have fun and stay safe!