While doing some research on ILProtector, I loaded my test executable in Olly. To much of my surprise, it refused to run and all I could see in Olly log, was this:
Log data
Address Message
OllyDbg v1.10
Command line: test.exe
Console file 'C:\test.exe'
ODbgScript v1.82.6 i686 VC2008 WDK7.1 CRT/STL60
http://odbgscript.sf.net
ScyllaHide Plugin v1.3
Copyright (C) 2014 Aguila / cypher
Hooked Olly Breakpoints handler for TLS at 0x2F918
New process with ID 00002E2C created
00FC404E Main thread with ID 00002754 created
[ScyllaHide] Reading NT API Information C:\Tools\Olly\Plugins\NtApiCollection.ini
[ScyllaHide] Hook Injection successful, Imagebase 00030000
00FC0000 Module C:\test.exe
CRC changed, discarding .udd data
748C0000 Module C:\Windows\SYSTEM32\MSCOREE.DLL
CRC changed, discarding .udd data
76070000 Module C:\Windows\syswow64\KERNEL32.dll
76180000 Module C:\Windows\syswow64\KERNELBASE.dll
CRC changed, discarding .udd data
77100000 Module C:\Windows\SysWOW64\ntdll.dll
CRC changed, discarding .udd data
771A103B System startup breakpoint
76650000 Module C:\Windows\syswow64\ADVAPI32.dll
CRC changed, discarding .udd data
...
5B820000 Module C:\Protect32.dll
CRC changed, discarding .udd data
76840000 Module C:\Windows\syswow64\OLEAUT32.dll
CRC changed, discarding .udd data
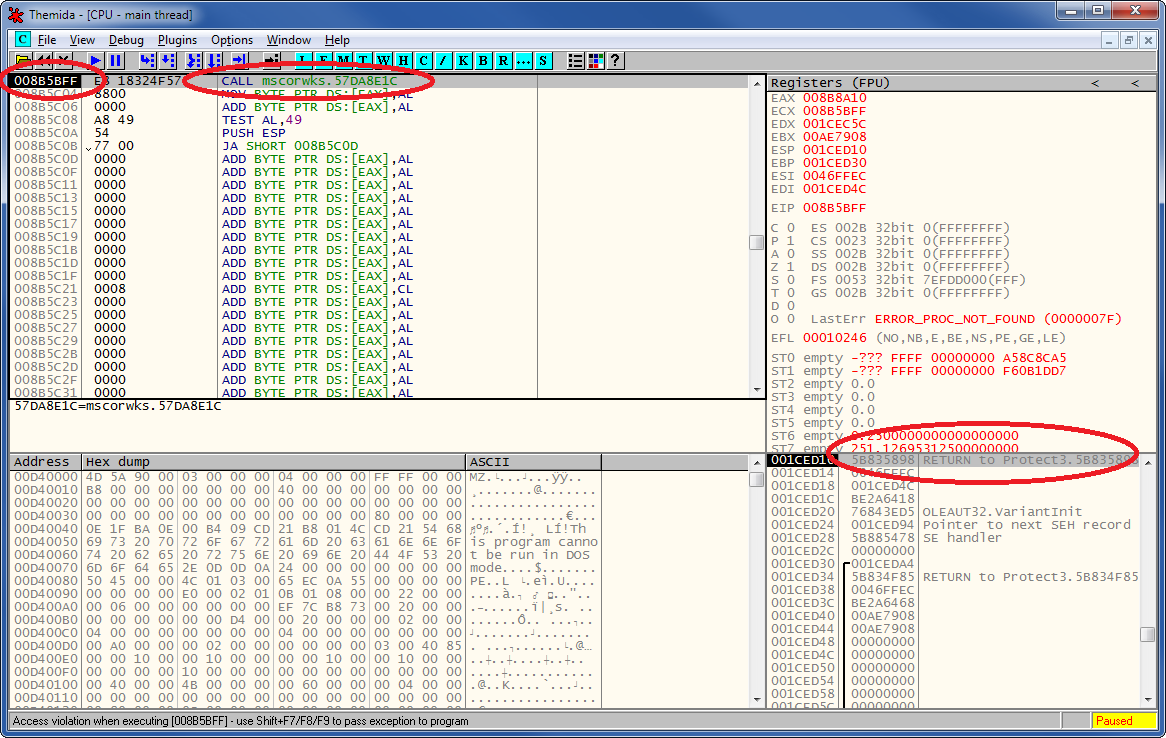
008B5BFF Access violation when executing [008B5BFF]
7618C42D Exception E0434F4D
7618C42D Exception E06D7363
7618C42D Exception E0434F4D
Debugged program was unable to process exception
Something smells fishy! 😉
I disabled all non-standard plugins, and I was still getting the exception. It was only after I removed the remaining 2 plugins (ScyllaHide and ODBGScript) that my test application launched. Few more restarts and I was sure that ScyllaHide is the one causing the trouble.
OK, I've found a bug in ScyllaHide. But where is it? Which option is causing it? And how can I fix it?
Unfortunately, there is no easy way. Just go through one option after another, until you trigger the bug. 10 minutes and 100 rude words later I was sure that "HeapFlags" is the culprit.
A side note from Captain Obvious
If you're seeing access violation in Olly and want to know where it's happening, make sure you uncheck Ignore Memory access violation in Debugging Options:
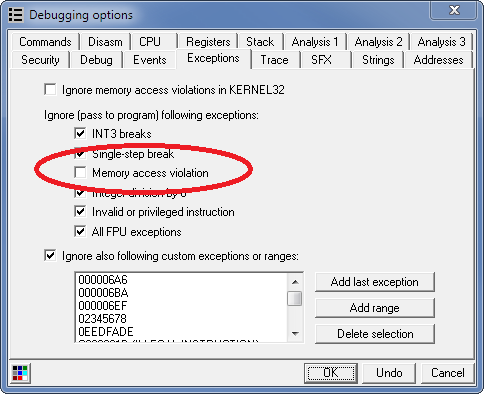
and then run your target:
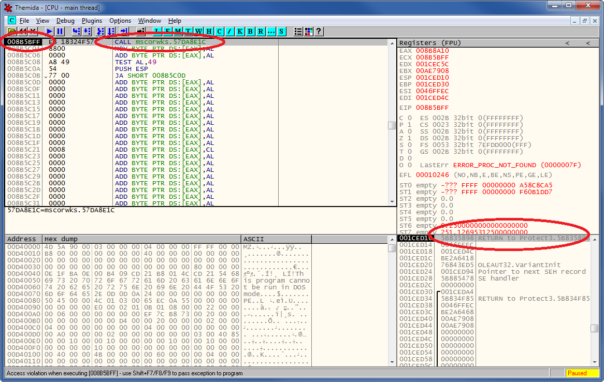
Here we can see that there is a real code at this address - small stub calling mscorwks.dll and that the call comes from ILProtector's protect32.dll.
It immediately gives you plenty of useful information about what's happening. Unfortunately I debugged one instance of Olly from another instance of Olly - got the same results but it took me much longer.
Meet HEAP_CREATE_ENABLE_EXECUTE
It turns out that .NET Runtime Execution Engine (mscoreei.dll) loves to put executable code on heap:
.text:1000A424 ; int __stdcall DllMainProcessAttach()
.text:1000A424 ?DllMainProcessAttach@@YGHXZ proc near ; CODE XREF: DllMain(x,x,x):loc_1000A6B4�p
...
.text:1000A591 push ebx ; dwMaximumSize
.text:1000A592 push ebx ; dwInitialSize
.text:1000A593 push HEAP_CREATE_ENABLE_EXECUTE ; flOptions
.text:1000A598 call ds:__imp__HeapCreate@12 ; HeapCreate(x,x,x)
.text:1000A59E mov ?g_ExecutableHeapHandle@@3PAXA, eax ; void * g_ExecutableHeapHandle
...
but ScyllaHide prefers to mark all heaps as non-executable:
if (ReadProcessMemory(hProcess, heapFlagsAddress, &heapFlags, sizeof(DWORD), 0))
{
heapFlags &= HEAP_GROWABLE;
WriteProcessMemory(hProcess, heapFlagsAddress, &heapFlags, sizeof(DWORD), 0);
}
and these 2 options kinda conflict with each other. 🙂
Workaround & fix
This small bug can be used to detect ScyllaHide, as it's enabled by default in all configurations, and tooltip explicitly suggests to leave it as-is:
Very important option, a lot of protectors check for this value.
Here is a suggested patch:
if (ReadProcessMemory(hProcess, heapFlagsAddress, &heapFlags, sizeof(DWORD), 0))
{
heapFlags &= (HEAP_GROWABLE | HEAP_CREATE_ENABLE_EXECUTE) ;
WriteProcessMemory(hProcess, heapFlagsAddress, &heapFlags, sizeof(DWORD), 0);
}
If you don't want to recompile the entire Scylla, here's the binary patch for the official ScyllaHideOlly1.dll from ScyllaHide_v1.3fix_Olly1.rar package:
00005A0B: 85 81
00005A0C: C0 65
00005A0D: 74 FC
00005A0E: 14 02
00005A0F: 83 00
00005A10: 65 04
00005A11: FC 00
00005A12: 02 90
As a simple workaround, you could uncheck "HeapFlags" in ScyllaHide when debugging .NET applications. However, I would really suggest to fix ScyllaHide instead.
Have fun and keep it safe!