Yesterday Extreme Coders posted a small crackme on Tuts4You. It's quite an easy one but solving it would require either lots of typing or some clever automation. Of course, being lazy I went for the automation route! 🙂
Initial analysis
My preferred way is doing static analysis in IDA and - when necessary do dynamic analysis using OllyDbg. So, here is how it looks like in IDA:

As you can see, parts of code have been encrypted. 102 parts of code, to be exact. 🙂
Decrypt the code
Since there is a lot of code that's encrypted, I need to automate decryption somehow. IDA scripting to the rescue!
auto ea;
auto addr;
auto size;
auto xorval;
auto x;
auto b;
ea = MinEA();
ea = FindBinary(ea, SEARCH_DOWN , "E8 00 00 00 00 5E 81 C6");
while (ea != BADADDR)
{
addr = ea + 5 + 0x16;
size = Dword(ea + 0xD);
xorval = Byte(ea + 0x15);
Message(form("Encrypted code parameters: start=%x size=%x key=%x\n", addr, size, xorval));
for (x=0; x<size; x++)
{
b = Byte(addr + x);
PatchByte(addr + x, b^xorval);
}
ea = FindBinary(ea +1, SEARCH_DOWN, "E8 00 00 00 00 5E 81 C6");
}
There's not much to comment. There's a big loop that's looking for the pattern of the decryption code. Then it extracts information about encrypted code address, size and used encryption key. Finally it decrypts the code.
Note - when you're patching binary data in IDA, it's always better to force IDA to reanalyze the affected fragment. I didn't do that here because changing end of _main() will force analysis automatically.
After decryption the code looks much better:
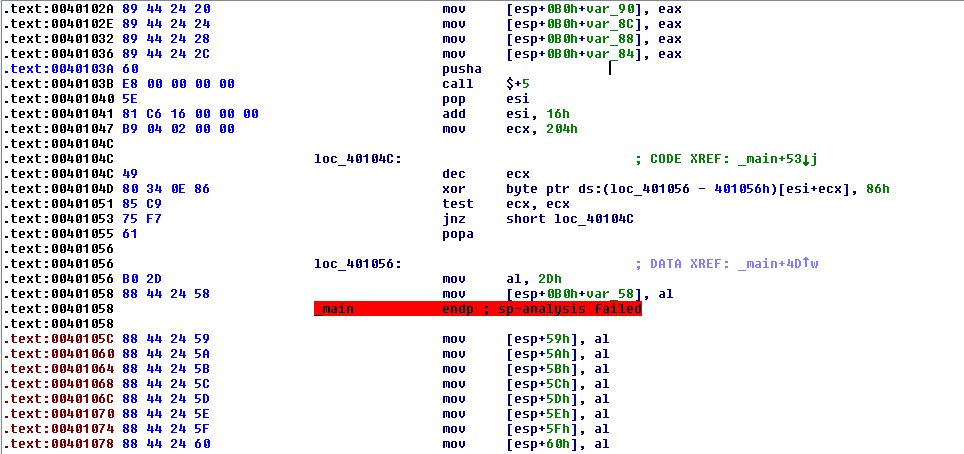
Well, it's better, but it still kinda sucks. We have 100 checks like this:
movsx edx, [esp+0B0h+enteredString+9] movsx ecx, [esp+0B0h+enteredString+13h] add ecx, edx movsx edx, [esp+0B0h+enteredString+0Bh] lea edx, [edx+ecx*2] movsx ecx, [esp+0B0h+enteredString+1Dh] add edx, ecx mov ecx, dword ptr [esp+0B0h+enteredString] movsx edi, ch add edx, edi movsx edi, [esp+0B0h+enteredString+6] add edx, edi movsx edi, [esp+0B0h+enteredString+2] add edx, edi movsx edi, [esp+0B0h+enteredString+4] add edx, edi movsx edi, [esp+0B0h+enteredString+0Fh] add edx, edi movsx edi, [esp+0B0h+enteredString+0Ah] add edx, edi movsx edi, [esp+0B0h+enteredString+0Ch] add edx, edi movsx edi, [esp+0B0h+enteredString+11h] add edx, edi movsx edi, [esp+0B0h+enteredString+18h] add edx, edi movsx edi, [esp+0B0h+enteredString+0Eh] add edx, edi movsx edi, [esp+0B0h+enteredString+1Ah] add edx, edi movsx edi, [esp+0B0h+enteredString+17h] add edx, edi movsx edi, [esp+0B0h+enteredString+16h] movsx ecx, cl add edx, edi add edx, ecx cmp edx, 787h jnz loc_40147B add eax, 1 <--- increment number of passed checks loc_40147B:
So, we're solving system of 100 linear equations with 32 variables. Great! Who wants to write down these equations based on disassembly and then solve them manually? Not me!
Decompile the code
Let's see if we can somehow make the problem easier for us. Hexrays decompiler provides nice output but it still needs a lot of cleanup:

Basically, the code responsible for encryption/decryption of checks is getting into our way.
Another IDA script to the rescue:
auto ea;
auto addr;
auto size;
auto xorval;
auto x;
auto b;
ea = MinEA();
ea = FindBinary(ea, SEARCH_DOWN , "60 E8 00 00 00 00 5E 81");
while (ea != BADADDR)
{
for (x=0;x<0x1C;x++)
{
PatchByte(ea+x, 0x90);
}
MakeUnknown(ea, 0x1C, 0);
MakeCode(ea);
ea = FindBinary(ea +1, SEARCH_DOWN , "60 E8 00 00 00 00 5E 81");
}
I took the previous script and modified it a bit. Now it finds both encryption and decryption loops and just nops them out. It also forces IDA to reanalyze the patched region - it's very important because otherwise IDA lost track of correct stack pointer and decompiled code was wrong.
Quick changes in Hexrays plugin options to use decimal radix and the decompiled code looks great!

Text editor magic
Beginning reversers commonly underestimate power of text editors. Sure, the Hexrays output we got is readable, but it's not really suitable for any sort of automated processing.
First, let's get rid of all extra spaces. Replace " " (2 spaces) with " " (one space). Repeat until no more matches. Now it looks like this:
if ( enteredString[0] + enteredString[22] + enteredString[26] + enteredString[20] + enteredString[10] + enteredString[7] + 3 * enteredString[14] + 2 * (enteredString[23] + enteredString[24] + enteredString[17] + enteredString[21] + enteredString[12] + enteredString[18]) == 2024 ) v6 = 1; if ( enteredString[0] + enteredString[22] + enteredString[23] ... 98 more ifs...
Put each equation on one line. Replace "\r\n +" (new line,space,plus) with " +" (space,plus). Replace "\r\n *" (new line,space,star) with " *" (space,star).
if ( enteredString[0] + enteredString[22] + enteredString[26] + enteredString[20] + enteredString[10] + enteredString[7] + 3 * enteredString[14] + 2 * (enteredString[23] + enteredString[24] + enteredString[17] + enteredString[21] + enteredString[12] + enteredString[18]) == 2024 ) v6 = 1; if ( enteredString[0] + enteredString[22] + enteredString[23] + enteredString[26] + enteredString[14] + enteredString[24] + enteredString[17] + enteredString[12] + enteredString[10] + enteredString[15] + enteredString[4] + enteredString[2] + enteredString[6] + enteredString[1] + enteredString[29] + enteredString[11] + 2 * (enteredString[9] + enteredString[19]) == 1927 ) ++v6; if ( enteredString[14] + enteredString[10] == 148 ) ++v6; if ( enteredString[0] + enteredString[14] + enteredString[10] + enteredString[11] + enteredString[3] + enteredString[25] + 2 * (enteredString[22] + enteredString[27]) == 741 ) ++v6; if ( enteredString[24] + enteredString[29] == 229 ) ++v6; ... 95 more ifs ...
Get rid of those "if". Get rid of "++v6;". Replace "==" with "=".
enteredString[0] + enteredString[22] + enteredString[26] + enteredString[20] + enteredString[10] + enteredString[7] + 3 * enteredString[14] + 2 * (enteredString[23] + enteredString[24] + enteredString[17] + enteredString[21] + enteredString[12] + enteredString[18]) = 2024 ) enteredString[0] + enteredString[22] + enteredString[23] + enteredString[26] + enteredString[14] + enteredString[24] + enteredString[17] + enteredString[12] + enteredString[10] + enteredString[15] + enteredString[4] + enteredString[2] + enteredString[6] + enteredString[1] + enteredString[29] + enteredString[11] + 2 * (enteredString[9] + enteredString[19]) = 1927 enteredString[14] + enteredString[10] = 148 enteredString[0] + enteredString[14] + enteredString[10] + enteredString[11] + enteredString[3] + enteredString[25] + 2 * (enteredString[22] + enteredString[27]) = 741 enteredString[24] + enteredString[29] = 229 ... 95 more equations ...
Finally, rename "enteredString" to "z" and get rid of those "[" and "]"
z0 + z22 + z26 + z20 + z10 + z7 + 3 * z14 + 2 * (z23 + z24 + z17 + z21 + z12 + z18) = 2024 ) z0 + z22 + z23 + z26 + z14 + z24 + z17 + z12 + z10 + z15 + z4 + z2 + z6 + z1 + z29 + z11 + 2 * (z9 + z19) = 1927 z14 + z10 = 148 z0 + z14 + z10 + z11 + z3 + z25 + 2 * (z22 + z27) = 741 z24 + z29 = 229 ... 95 more equations ...
Congratulations, within one minute you got from ugly decompiled code to well-written system of equations!
And solve the problem
Nicely written system of equations is pointless, if you can't solve it. Luckily, there's an online solver for that right there! 😉 Copy-pasting our cleaned system of equations into their webform gives us result:
This system has a unique solution, which is
{ z0 = 102, z1 = 108, z10 = 48, z11 = 108, z12 = 118, z13 = 101, z14 = 100, z15 = 95, z16 = 116, z17 = 104, z18 = 97, z19 = 116, z2 = 97, z20 = 95, z21 = 114, z22 = 49, z23 = 103, z24 = 104, z25 = 116, z26 = 33, z27 = 33, z28 = 33, z29 = 125, z3 = 103, z4 = 123, z5 = 89, z6 = 48, z7 = 117, z8 = 95, z9 = 115 }.
Converting character codes to ANSI string is an equally simple exercice, I'm not gonna bore you with that.
And that's how you solve a crackme with nothing but a few scripts in IDA and a text editor.. 😉



{kind=link}
{kind=link}
{kind=link}